
LLMs from the Inside 1: Tokenization
Hi guys! John the Quant here. In this series of articles, we are going to explore each piece of the architecture that makes models like GPT, Llama, and Claude possible. All of the big, generative Large Language Models follow the same basic architecture. It looks like this:
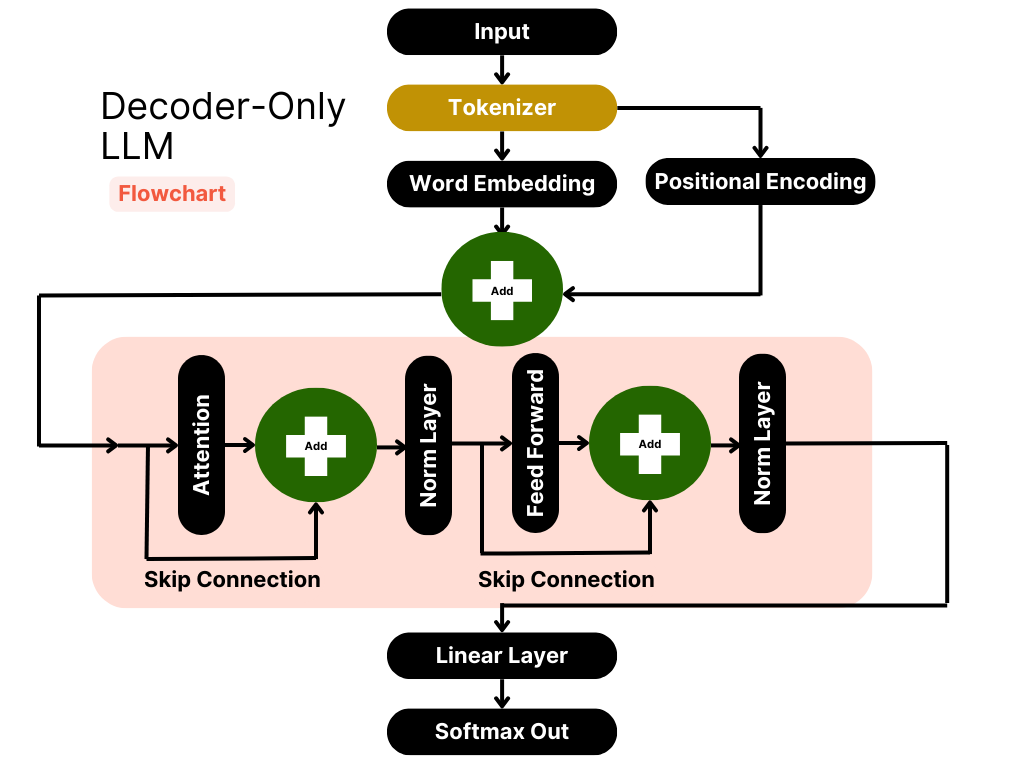
All the famous Generative LLMs follow this architecture.
As we talk about each piece, we are going to explore different implementation options, which famous models use which option, and why the designers made that choice.
Let’s get started.
Tokenizer
A tokenizer takes text and turns it into numbers. The numbers don’t have to have meaning yet, but the way you split up the text matters! It turns out that language isn’t just a combination of letters, but rather combinations of combinations of letters.
There are three different ideas for tokenization in the picture below. The first two do not work well for most general purposes. Word tokenization makes it hard to learn the connection between “sit” and “sitting”. Letter tokenization makes it impossible to learn the meaning of any word because words don’t exist. By tokenizing meaningful word fragments, we can preserve the meaning of words and highlight the relationships between similar words. Note how “sitting” becomes “sit t ing” and “cats” becomes “cat s”. This means the model can learn the present tense and plural words, which it couldn’t in either of the other tokenization schemes.

Three ideas for how to tokenize text. The third idea allows language understanding that the first two can’t!
It is pretty obvious that sub-word tokenization allows the tokens to be semantically powerful in ways that character and full-word tokenization do not. But now we need a way to apply sub-word tokenization to huge amounts of text. That’s the tough bit. We could assign rules, like I did in the picture, simply separating prefixes/suffixes from the root word, but there are two big problems with that approach:
There are a LOT of language rules, prefixes, suffixes, and root words. The present participle of “sit” is “sitting”, but the present participle of “wait” is “waiting”. Sitting has an extra “t” that separates it from the root word, while “waiting” doesn’t. How would we represent that in the word-fragmentation rules? It might be technically feasible to write a comprehensive list, but it would certainly be tedious and expensive.
If we assign rules, we can’t discover anything new. It’s the difference between being told the answer and learning the material. But if we allow a data-driven system to devise its own word-fragmentation rules, it will likely find patterns that aren’t directly linked to known language rules. A good automated word-fragmentation system will split words in ways that a human probably wouldn’t. And that’s a good thing. Not only will the AI learn better, but we can learn from it, too.
There are three common word-fragmentation and tokenization algorithms, each popular in a certain context. Let’s look at them now.
Byte-Pair Encoding
This is the most common tokenization scheme and is the #1 choice for generative models. Byte-Pair Encoding (BPE) is used by all the GPT models, Llama 3, Gemini, ELECTRA, BART, and more. And it’s a relatively simple idea.
The original BPE algorithm was actually devised for text compression, way back in 1994. It’s been around a while. If two bytes (or characters) occur together often, treat them as a single unit. That’s it. Here’s some pseudocode for the algorithm.

Short and sweet. Just the way an algorithm should be.
Let’s also do an example together!
Byte-Pair Encoding Example

Start with each character as a token.
The most common pair is “at”, so we add that to the vocabulary.

See how we start putting byte-pairs together?
Now there is no single most-common pair, so just pick the first pair with the highest frequency: “th”.

Now we’ve replaced two token-pairs!
That’s Byte-Pair Encoding, the most popular tokenization technique for Generative AI in use today.
WordPiece Encoding
WordPiece is quite similar to Byte-Pair Encoding. This tokenization algorithm was developed by researchers at Google and first used to train the BERT model. Descendents of BERT like ALBERT and RoBERTa also make use of WordPiece Encoding. BPE is the most popular tokenization algorithm for decoder-only models and WordPiece is the favorite for encoder-only models.
There are just three big differences between Byte-Pair Encoding and WordPiece Encoding:
Byte-Pair Encoding uses pair frequency to merge tokens. WordPiece uses an importance score similar to TFIDF vectorization. See the picture below.
In WordPiece, subwords are identified by a prefix. For BERT, the prefix is “##”. For example, the word “friendly” would start off tokenized as [“f”, “##r”, “##i”, “##e”, “##n”, “##d”, “##l”, “##y”], and may end up tokenized as [“friend”, “##ly”].
In Byte-Pair Encoding, we kept all of the intermediate pairs. In WordPiece, we keep only the final vocabulary. This means WordPiece only captures more meaningful subwords, but it also means there are pairings that WordPiece does not capture. Less noise, but also less signal.

WordPiece’s Importance Score.
The frequency of the pair divided by the product of individual token frequencies. If the pair occurs often relative to the individual tokens, the score will be high. If the individual tokens occur often relative to the pair, the score will be low.
Other than that, the two algorithms are identical.

A little longer than Byte-Pair Encoding, but still not too complicated.
WordPiece Example
Let’s do the same example as with Byte-Pair Encoding so we can directly compare the two algorithms. The sentence is “The fat cats are sitting on the mat.”

WordPiece treats the start of the word differently!
Now we can calculate the scores. It’s easier to do by counting token frequencies, then counting pair frequencies, then calculating the score.

The score is calculated by dividing the pair frequency by the product of the individual token frequencies.
The pair with the highest score is (9, 10), or (“a”, “##r”), so we put those together and add “ar” to the vocabulary. Now, neither token 9 (“a”) nor 10 (“##r”) appear in the text, so we remove those two from the vocabulary. Then repeat the procedure.

As you put tokens together to form subwords, the Tokenized Words will get shorter.
This time, the highest score is 0.5 and several pairs have that score. Just pick the first pair with that score and put them together. Thus, (“t”, “##h”) becomes “th”. Again, “t” and “##h” no longer appear in the text so we delete them from the vocabulary.

The output from our WordPiece Encoding Example
We can repeat that procedure over and over to build a large token vocabulary.
The tokenization produced by WordPiece was very different from the tokenization produced by Byte-Pair Encoding. By using the importance score rather than raw frequency, WordPiece tries to determine which subwords are semantically important. The focus on meaning makes WordPiece the right choice for meaning-focused LLMs like BERT. By using raw frequency, Byte-Pair Encoding determines which subwords occur most often. The focus on frequency makes BPE the right choice for probability-focused LLMs like GPT, Llama, and other generative models.
SentencePiece
SentencePiece is kind of a different animal and deserves its own complete article; but it is an important tokenization algorithm so here’s a brief overview. Before we go further, know that SentencePiece is a specific implementation of the general idea of subword regularization. More on that in a couple of paragraphs.
The most important thing to know about SentencePiece is that it works in any language. Byte-Pair Encoding and WordPiece only work in Western languages with alphabets and whitespace between words. SentencePiece was designed for Neural Machine Translation, specifically to solve the problem other tokenizers have with non-Western language. SentencePiece is lossless in all languages.
One of the major difficulties with tokenizing Western vs. Eastern language is whitespace. In English, for example, we use spaces to separate words. But in Burmese, there is no space between words. SentencePiece treats whitespace very simply: The preceding space counts as part of the word and is replaced with “_”.

How would you tokenize Burmese text?
Subword Regularization
Byte-Pair Encoding creates a lot of subwords. Since all subwords are kept, you might end up with a vocabulary like [“a”, “b”, “c”, “l”, “o”, “r”, “u”, “v”, “y”, “ab”, “ar”, “la”, “ry”, “vo”, “ary”, “ary” “voc”, “lary”]. That gives you many options for how to split up the word “vocabulary”. You could use the longest subwords ([“voc”, “ab”, “u”, “lary”]). You could split every letter ([“v”, “o”, “c”, “a”, “b”, “u”, “l”, “a”, “r”, “y”]). You could do something in between. So which one is best? That’s the question subword regularization tries to answer.
Each possible tokenization creates a sequence of tokens that we can treat probabilistically.

This equation is derived using Bayes Theorem, but it’s intuitive, too. Each step depends on all preceding steps.
We’re skipping a few steps here (watch out for a full-length dive into SentencePiece), but we end up with the following log-likelihood function.

Don’t be afraid. It’s just the sum of the log-probability of the sequences.
We want tokenizations that maximize the likelihood. There is a procedure for doing so:
Get the initial probability for each token.
Compute the sequence with the maximum likelihood.
Recompute probabilities for each token given the maximum likelihood tokenization. We can do this by counting the occurrences of each token in the maximum likelihood tokenization.
Repeat steps 2 and 3 until probabilities converge.
At this point, we have informed probabilities for every token in our vocabulary. To perform subword regularization, throw away the improbable tokens. Either discard the k% of the vocabulary with the lowest probability or discard all tokens with probability below some cutoff.
This often still leaves us with many possible tokenizations for each input sequence, so the final step is to generate token-sequences with high likelihoods. One way of doing this is with the Forward-Filtering Backward-Sampling algorithm, or FFBS. A full explanation of FFBS is beyond the scope of this article, but the basic idea is to calculate conditional probabilities from left-to-right, then sample from those probabilities right-to-left. Forward Filter, Backward Sample. FFBS is less computationally expensive than other methods, such as Gibbs Sampling.
SentencePiece was used by Llama 1&2, T5, and XLNet. I do not think Llama 3 uses SentencePiece. The design of SentencePiece makes it a great choice for lighter models and models that need to be used in multiple languages, as it is lossless in every language and the additional regularization may make learning more efficient.
Conclusion
Transformers get all the attention, but every part of the model is important. Tokenization is the entryway to the rest of the model; if your tokenization is bad, the rest of your model will not learn. In this article, we looked at the three most common tokenization algorithms in use in LLMs today.
Byte-Pair Encoding — This algorithm forms subwords by determining which pairs of bytes or characters occur together frequently. It is simple and fast and generates tokens based solely on usage, making it a great choice for generative models.
WordPiece Encoding — This algorithm forms subwords by calculating the relative frequency of the pair versus the individual tokens. It is more computationally expensive than BPE but is more likely to create semantically meaningful tokens, making it a great choice for classification and analysis.
SentencePiece Encoding — This algorithm takes a vocabulary generated by any tokenization scheme and helps determine the best tokenization possible with that vocabulary. It can be used to reduce the size of the vocabulary and simplify the learning process and is lossless in any language, making it a great choice for generative applications and translation.
When choosing a tokenizer for your project, be sure to keep the end goal in mind. It matters more than you think.
Tokenization is one area of NLP where small changes can lead to large gains. Being up to date on advances in tokenization is necessary for continued success as an NLP practitioner. Keep watch for new developments, let me know if you see something intriguing, and I’ll do the same.
Thanks for reading!